커뮤니에서 한분이 GCP 그리고 BigQuery 에 대하여 타 시스템과의 비교를 요청하셔서 장문의 답변을 하게 되었다. 해당 내용을 이곳에 옮겨 적어 보았다.
우선, 서두는 내가 시작하였다. 대략 이런 내용이었다.
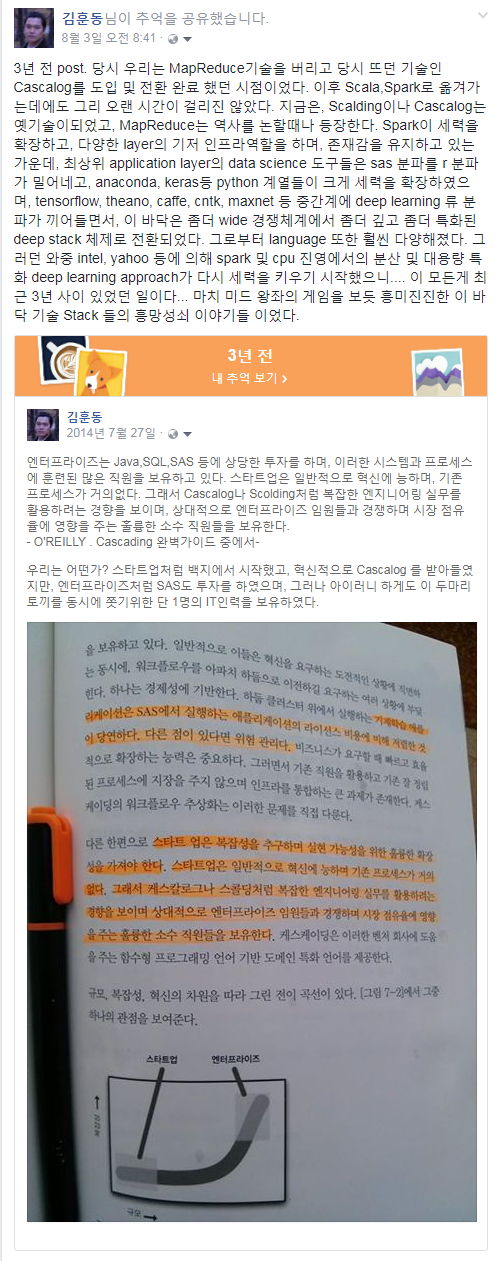
3년 전 post. 당시 우리는 MapReduce기술을 버리고 당시 뜨던 기술인 Cascalog를 도입 및 전환 완료 했던 시점이었다. 이후 Scala,Spark로 옮겨가는데에도 그리 오랜 시간이 걸리진 않았다. 지금은, Scalding이나 Cascalog는 옛기술이되었고, MapReduce는 역사를 논할때나 등장한다. Spark이 세력을 확장하고, 다양한 layer의 기저 인프라역할을 하며, 존재감을 유지하고 있는 가운데, 최상위 application layer의 data science 도구들은 sas 분파를 r 분파가 밀어네고, anaconda, keras등 python 계열들이 크게 세력을 확장하였으며, tensorflow, theano, caffe, cntk, maxnet 등 중간계에 deep learning 류 분파가 끼어들면서, 이 바닥은 좀더 wide 경쟁체계에서 좀더 깊고 좀더 특화된 deep stack 체제로 전환되었다. 그로부터 language 또한 훨씬 다양해졌다. 그러던 와중 intel, yahoo 등에 의해 spark 및 cpu 진영에서의 분산 및 대용량 특화 deep learning approach가 다시 세력을 키우기 시작했으니.... 이 모든게 최근 3년 사이 있었던 일이다... 마치 미드 왕좌의 게임을 보듯 흥미진진한 이 바닥 기술 Stack 들의 흥망성쇠 이야기들 이었다.
이후 여러 말들이 오가던 중 질문...
Question )
전문가께 GCP, 빅쿼리에 대한 간단한 인상? 감상을 여쭤도 될까요? 자투리 시간에 공부해볼까 하는 중입니다.
그리고, 답변이다. 너무 장문이었나??? 여튼 아까워서 이곳에 옮겨 적었음.
Answer )
요즘 IaaS 는 AWS나 Azure 나 비슷비슷하죠. 가격도 거의 판박이구요. 단, AWS 가 커뮤니티나 3rd Party 쪽 Pre Built 이미지가 많아서, IaaS 에서는 좀 앞서는거 같구요. GCP는 셋중에 좀 밀리구요. PaaS 로 넘어가면, Azure 가 AWS 보다 종류도 많고, 완성도도 좀더 높은게 확실히 느껴지구요. GCP 의 경우는 Serverless 아키텍처에서 카날리 배포 하는 부분이랄지, Big Query 부분 등이 확실히 차별 point가 있는거 같아요. 무엇보다 Tensorflow 를 리딩하는 곳 답게, Deep Learning 에 있어, TPU 라던지.... Tensorflow Serving Layer 를 위한 PaaS 부분이 AWS 나 Azure 와는 확실히 다른 장점을 보유하고 있습니다. Big Query 는 대용량 데이타에 대하여 확실히 속도도 빠르고, 다양한 쿼리나 연산도 지원하여, 사내 BigData 업무에 있어서 확실히 큰 역할을 해낼 수 있습니다. 단, POC나 Toy Project, 혹은 Hands on Lab 수준의 요건이 아닌 실제 BigData Scale Business 요건에서 만나는 복잡다난한 요건에 대하여는 그런류의 Query Platform 은 한계가 있는 경우가 많아서, 대체 시스템 이라기 보다는 One of Them 보완 시스템으로 positioning 하고 접근 하셔야 합니다. NoSQL에 은총알이 없는 것과 비슷한거죠. BigQuery 도 BigQuery 가 지원하지 않는 기능에 대한 보완을 위해 UDF 를 지원하지만,(Hive 도 UDF를 지원하죠..) Hive 가 그러하듯이, Hive 만 가지고, 모든 요건을 해결할 순 없으니까요. 100배 빠른 Hive 가 있다 할지라두요. 가끔 Numpy 가 필요할때도 있죠. Konlpy 가 필요할때도 있구요. R에만 구현되어 있는 어떤 알고리즘이 필요할 때도 있습니다. 그런데, single machine R로는 로딩도 안되는게 문제죠. 복잡한 실무 Real Wordl Business Logic 을 Query 로만 구현할려고 하면, 병렬시스템 최적화 Plan 짜기가 너무 복잡 할때는 Scala 같은 Function Langauage 로 일일이 Parallel 구현 Step 을 구현 해주고 싶을 때가 있습니다. (실무에서는 Dw로직을 BigData 로 옮길때, A4용지 4~5장짜리 한방 쿼리들도 많이 접합니다. 그걸 옮길때는 Query 보다 Code 가 훨씬 편합니다. 대게의 경우 그런 Mart 성 R-Olap Query를 그대로 이관하면, NoSQL 이나 Cloud DW 에서는 대부분 돌지 않거나, 매우 느려집니다.)
또한, Java 로도 Hive 로도 Spark SQL 이나 Spark ML 로도 안되는 그러한 요건들은 Python 이나 R로 하는게 절대적일때가 있는데, 대용량이 안되면, Spark 위에 PySpark 로 Model Parallelism 이 안되면, Data Parallelism 이라도 꽤하는게 크게 도움이 될때가 있습니다. SparkR 보단 MS R on Spark 나 Spakly R로 도움을 받을 수도 있구요. 요즘은 Tensorflow 나 Keras 도 Spark 위에서 Data Parallelism 이 가능하죠. BigDL 을 쓰면 Deep Learning 에 대하여 Model Parallelism 도 되구요. 여튼 BigQuery 는 훌륭한 General 도구인 것은 맞구요. 역시 은총알은 아니다 정도만 주지하시면 될 듯 해요. 이바닥이 Wide 하게 춘추전국이 아니라, 어느정도 교통정리가 되어가는 대신, 각 분야에 Specialty 를 극대화 하는 쪽으로 치닫고 있어서, Stack 이 매우 깊어졌습니다. 그리고, 실무에서 대용량의 요건을 가지고 Machine Learning 이나 Deep Learning 을 할라손 치면, 단순한 전처리만 하더라도 Anaconda + Python 단일 머신으로는 택도없는 경우가 허다하구요. 이를 위해서는 또다른 도구도 각 Stack 에 한두개 정도씩은 익힐 필요가 있습니다. 실무에서 Deep Learning 프로젝트를 하다 보니, 느낀 점은.... 우리가 Lab 에서 논문쓰고 있는게 아니기 때문에, Deep Learning 자체는 알려진 State of Art 접근 방식 및 해당 알고리즘의 가장 잘 알려진 github 구현체를 가져다 쓰면 되기 때문에, 큰 진입 장벽이 아니었다는 거구요. 오히려 진입 장벽은 A 부터 Z 까지..그리고 AI 의 Serving Layer 까지 그 전체를 아우르는 큰 시스템이 하나로 잘 엮이게 묶는 것이었습니다. 거의 Engineering Art 에 가깝구요... Model 하이퍼 파라미터 튜닝하는것보다, 그 모델을 다수의 동접의 사용자들에게 에러없이 동접을 버티며 Serving 하고, 그 반응이 다시 모델에 input 으로 들어가며, 운영 중 무중지로 rolling upgrade 시키는 걸 잘 구성하는게 5배 쯤 더 손이 많이가고 훨씬 고 난이도 테크닉을 필요로 했다 입니다. 그러던 와중에 대용량 데이타 전처리 부에 있어서는 BigQuery 가 일부에 있어서 큰 역할을 할 수 있습니다. Data Pipe Line 에서 물리적 셔플이 많이 일어나면 안되기 때문에, IaaS 나 PaaS 는 그런 도구들과 맞물려 통일화 고려도 필요하구요. BigData Scale 전처리 요건에 R 이나 Python 등을 섞어 쓰고 싶을때는 클라우드 상에서라면, BigQuery 보다는 Azure ML Studio 나 Data Lake 가 적당할 수도 있습니다. On Premise 라면 Spark 위에서의 Collaboration 을 구성하면 되구요.또한, Java 로도 Hive 로도 Spark SQL 이나 Spark ML 로도 안되는 그러한 요건들은 Python 이나 R로 하는게 절대적일때가 있는데, 대용량이 안되면, Spark 위에 PySpark 로 Model Parallelism 이 안되면, Data Parallelism 이라도 꽤하는게 크게 도움이 될때가 있습니다. SparkR 보단 MS R on Spark 나 Spakly R로 도움을 받을 수도 있구요. 요즘은 Tensorflow 나 Keras 도 Spark 위에서 Data Parallelism 이 가능하죠. BigDL 을 쓰면 Deep Learning 에 대하여 Model Parallelism 도 되구요. 여튼 BigQuery 는 훌륭한 General 도구인 것은 맞구요. 역시 은총알은 아니다 정도만 주지하시면 될 듯 해요. 이바닥이 Wide 하게 춘추전국이 아니라, 어느정도 교통정리가 되어가는 대신, 각 분야에 Specialty 를 극대화 하는 쪽으로 치닫고 있어서, Stack 이 매우 깊어졌습니다. 그리고, 실무에서 대용량의 요건을 가지고 Machine Learning 이나 Deep Learning 을 할라손 치면, 단순한 전처리만 하더라도 Anaconda + Python 단일 머신으로는 택도없는 경우가 허다하구요. 이를 위해서는 또다른 도구도 각 Stack 에 한두개 정도씩은 익힐 필요가 있습니다. 실무에서 Deep Learning 프로젝트를 하다 보니, 느낀 점은.... 우리가 Lab 에서 논문쓰고 있는게 아니기 때문에, Deep Learning 자체는 알려진 State of Art 접근 방식 및 해당 알고리즘의 가장 잘 알려진 github 구현체를 가져다 쓰면 되기 때문에, 큰 진입 장벽이 아니었다는 거구요. 오히려 진입 장벽은 A 부터 Z 까지..그리고 AI 의 Serving Layer 까지 그 전체를 아우르는 큰 시스템이 하나로 잘 엮이게 묶는 것이었습니다. 거의 Engineering Art 에 가깝구요... Model 하이퍼 파라미터 튜닝하는것보다, 그 모델을 다수의 동접의 사용자들에게 에러없이 동접을 버티며 Serving 하고, 그 반응이 다시 모델에 input 으로 들어가며, 운영 중 무중지로 rolling upgrade 시키는 걸 잘 구성하는게 5배 쯤 더 손이 많이가고 훨씬 고 난이도 테크닉을 필요로 했다 입니다. 그러던 와중에 대용량 데이타 전처리 부에 있어서는 BigQuery 가 일부에 있어서 큰 역할을 할 수 있습니다. Data Pipe Line 에서 물리적 셔플이 많이 일어나면 안되기 때문에, IaaS 나 PaaS 는 그런 도구들과 맞물려 통일화 고려도 필요하구요. BigData Scale 전처리 요건에 R 이나 Python 등을 섞어 쓰고 싶을때는 클라우드 상에서라면, BigQuery 보다는 Azure ML Studio 나 Data Lake 가 적당할 수도 있습니다. On Premise 라면 Spark 위에서의 Collaboration 을 구성하면 되구요.

참고로 Azure 상의 Data Lake 는 기저에 Hadoop 과 Spark 이 있다. 그래서 BigQuery 보다 느릴 순 있으나, Spark이 가지고 있는 확장성을 꽤할 수 있다. 바로 python, java, scala, R, 그리고 Hive SQL 을 쓸 수 있을 뿐 아니라, Spark Cluster 위에 약간의 부가 세팅을 하면, Deep Learning 에 있어, BigDL(made by Intel)로 Model Parallelism 을 꽤할 수 있고, tensorflow on spark(made by Yahoo) 혹은 keras + tensorflow + spark 로 Parallel 하이퍼파라미터 옵티마이제이션 및 앙상블 등을 꽤할 수 있다.
아래는 HDInsight 위에서 BigDL 을 쉽게 설치하는 가이드 문서 이다.
https://software.intel.com/en-us/articles/deploying-bigdl-on-azure-data-science-vm